TF-IDF(Term Frequency - Inverse Document Frequency)和餘弦相似性是整套系統很重要的部分,主要用來建立整個問答集的模型,還有比對使用者輸入的句子和問答集的哪一句最相似。
TF-IDF
TF-IDF 分為兩個部分,TF 和 IDF。(IDF 由 DF 轉換而來)
以五個擷取自問答集的問句為例,經過斷詞之後,問句會變成表中的格式。
| 編號 | 問句 |
|---|---|
| 0 | ['如何', '申請', '長期', '照顧', '服務', '及', '流程', '為', '何', '?'] |
| 1 | ['申請', '長照', '服務', '有', '什麼', '條件', '?'] |
| 2 | ['長期', '照顧', '服務', '項目', '有', '哪些', '?'] |
| 3 | ['何謂', '是', '「', '居家', '服務', '」', '?'] |
| 4 | ['何謂', '「', '喘息', '服務', '」', '?'] |
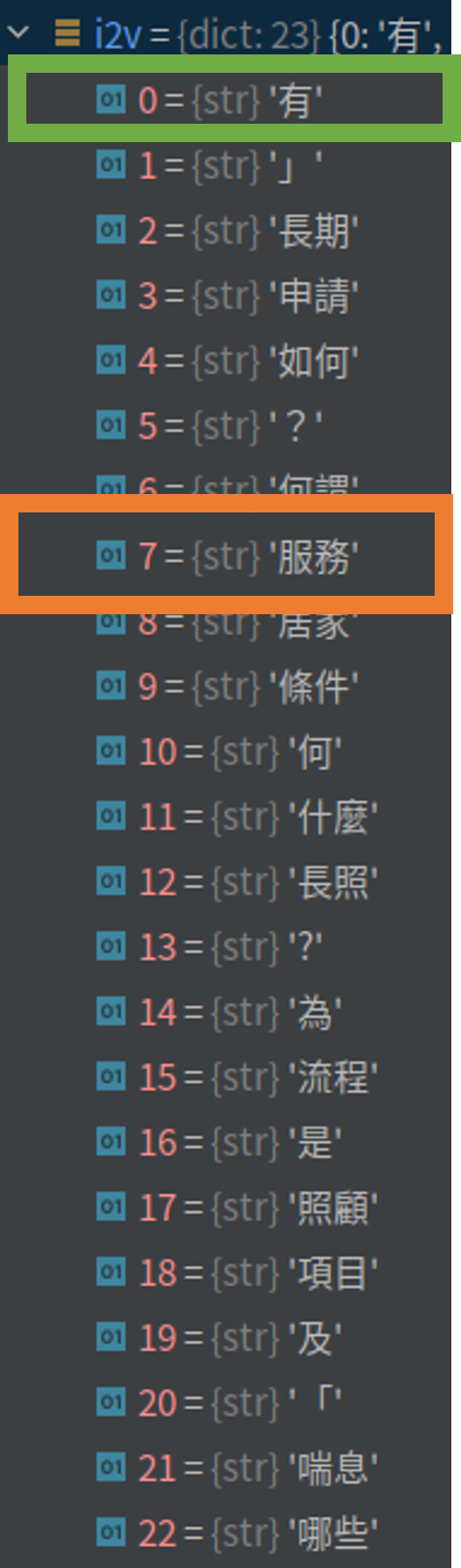
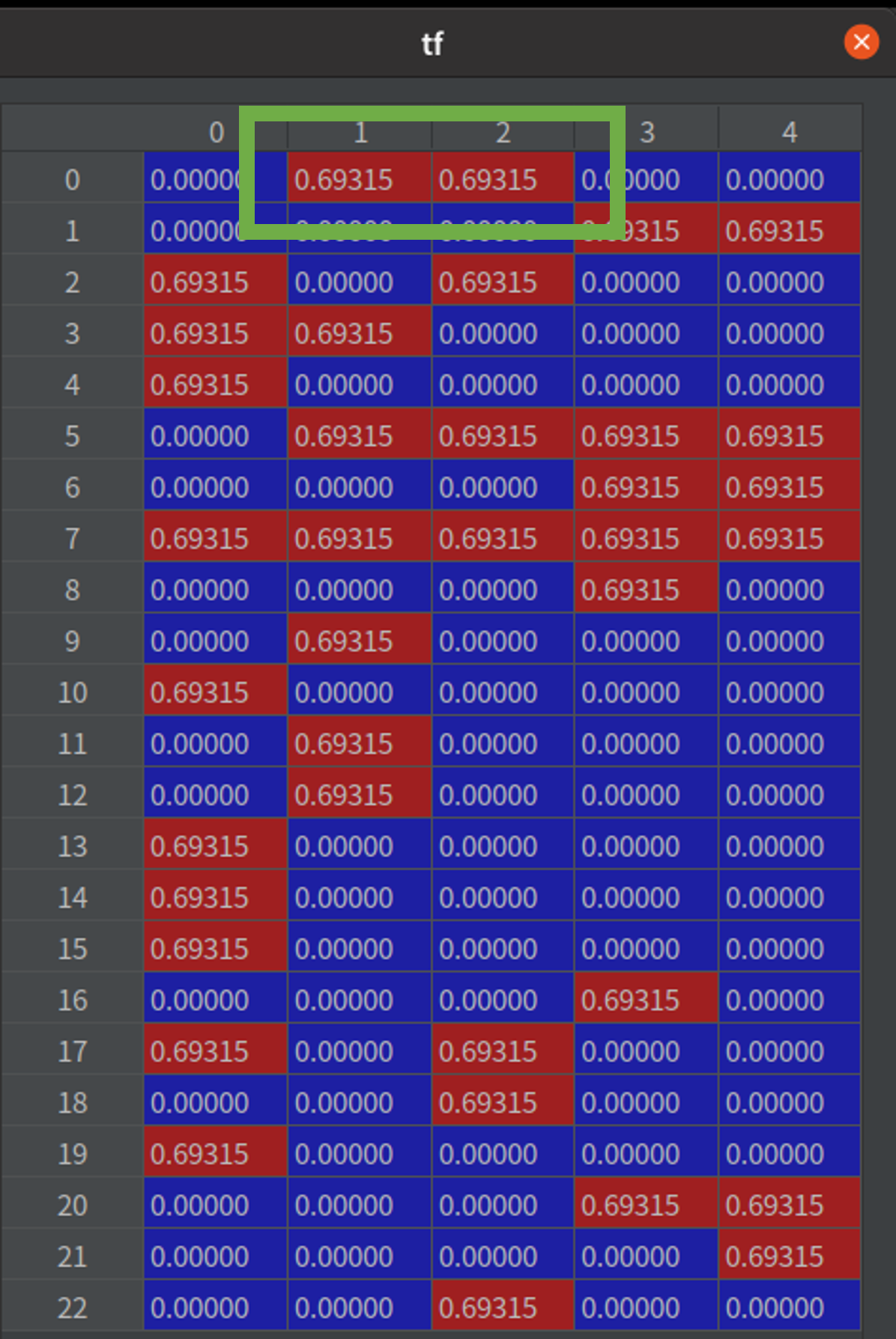
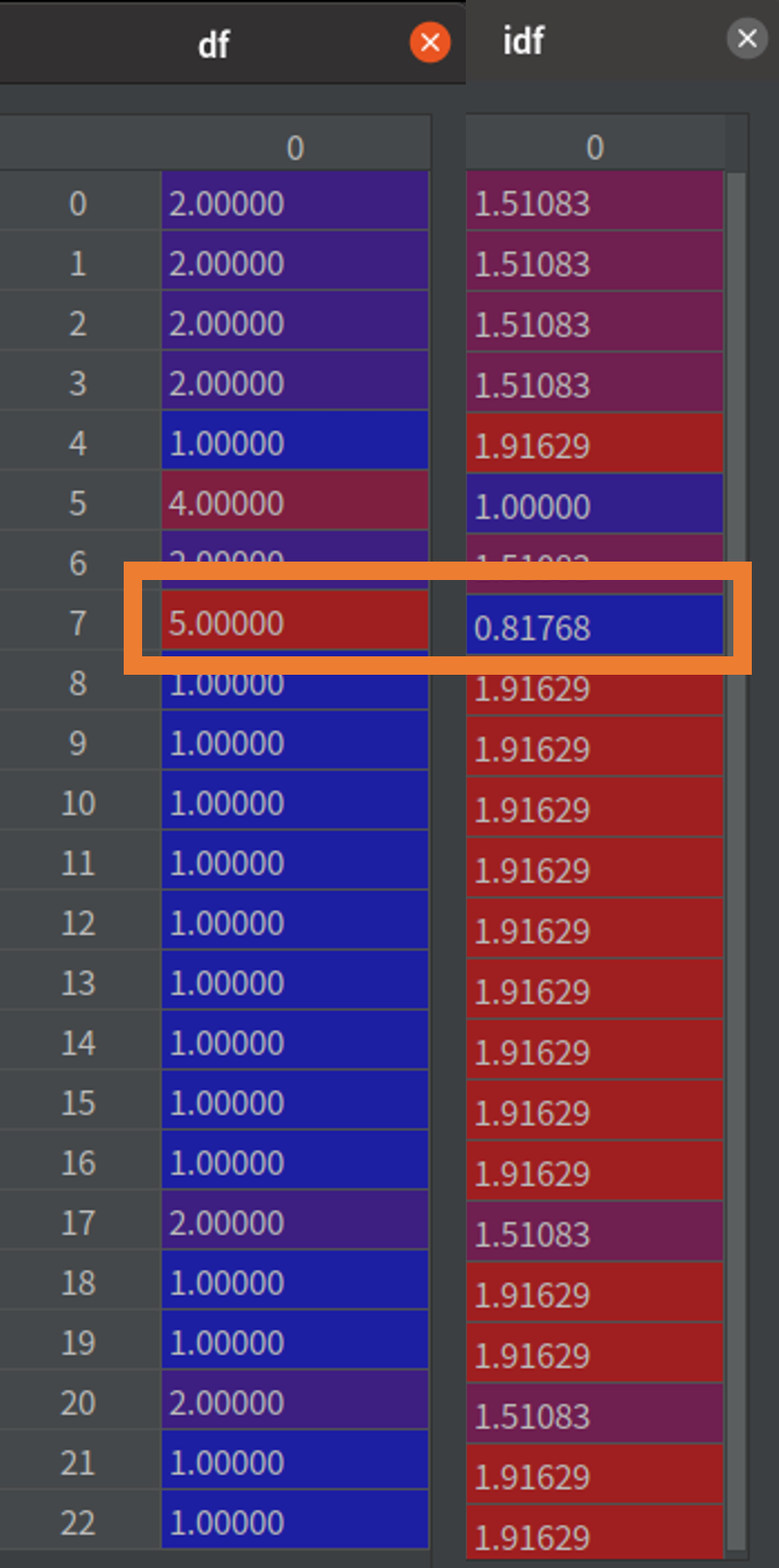
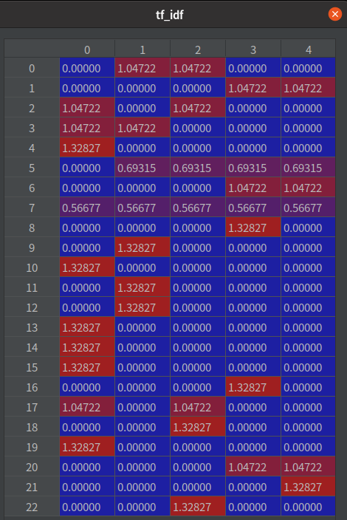
首先,我們會把所有的詞整理成一個集合(圖 1)。再統計每個詞出現在句子中的頻率,例如,「有」出現在第 1、2 句(參考 表格 1、圖 1 綠框、圖 2 綠框)。再統計一個詞出現在幾個句子中,例如,「服務」在五個句子都有,所以相對的 IDF 值就會比較小(參考 表格 1、圖 1 橘框、圖 3 橘框)。IDF 可以被當作是一個權重,用來表示這個詞的重要程度,把 TF * IDF 就會得到這個資料集的模型(圖 4)。
TF-IDF 使用餘弦相似性公式計算出輸入的問句與問答集中每個問題的相似性,再找出相似性最高的前三筆,回傳給使用者端 APP 使用。
TF-IDF 可以計算出每個詞在句子中權重分布的狀況,再透過餘弦相似性比較輸入的句子與問答集中每個問題的相似性,最後找到與輸入句子最相符的問答組合。
我們用程式畫了一張圖,每一列代表一個句子,每一欄代表一個詞,顏色深淺代表這個詞在這個句子中的重要性。如截圖所示,欄位個別代表一個句子,每一列則代表每一個詞,由這個矩陣可以觀察到所有權重的分佈狀況。

因整個問答集的問句及詞語太多,完整的截圖放在文中不易閱讀,因此本文中僅使用部分問句與詞語生成圖表示意。
這些句子都可以當成是一個一個的向量,當然他的維度比較高,我們這邊就以二維的做示意圖,餘弦相似度無關乎向量大小,重點是向量之間的方向。
本文以二維示意圖說明,假設資料集中有 A、B 兩個句子,C 是要比對的句子。當把 C 放進來一起比較就可以看出,C 和 B 的餘弦相似性比 C 和 A 大。
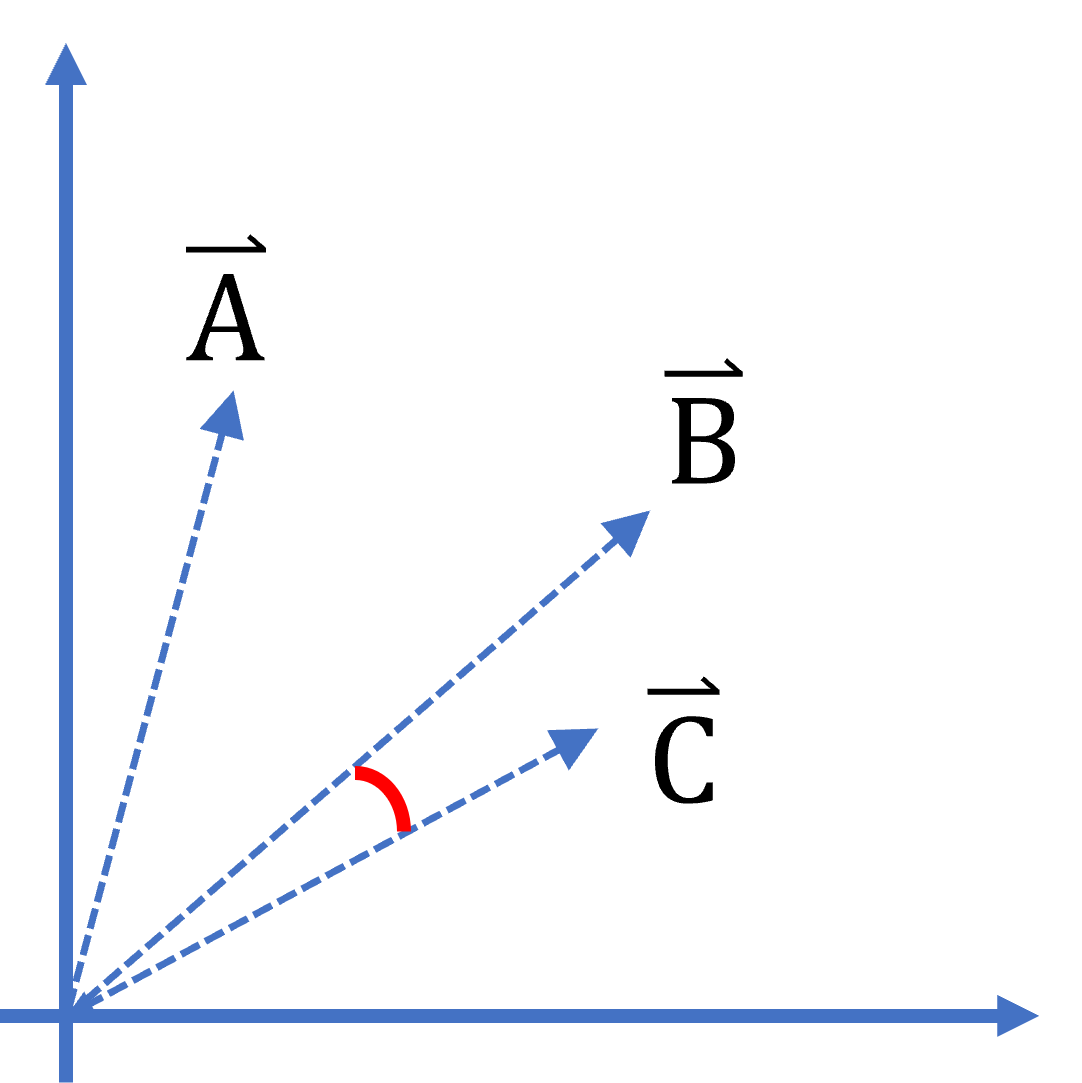
透過 TF-IDF 建立模型,再使用餘弦相似性比對句子間的相似性。基本上本系統最核心的部分就是這兩個部分了。


 iThome鐵人賽
iThome鐵人賽